I recently finished my Bachelor's thesis here at DigiTrace GmbH.
Its topic is the testing of tools that forensic
investigators use everyday, with respect to the anti-forensic risk
they might face during their work.
This page presents the test cases I created during my work, labeled under
the project title STARFiSH. It is especially meant for practitioners. For a deeper insight into the theoretical background and for more details concerning the information presented on this website please consider downloading the thesis using the link below.
The following is a citation of the thesis' abstract:
The goal of this thesis is to find an improved way to deal with the ever-growing anti-forensic risk. The situation today is that most testing is conducted unstructured and insufficiently organised. We present a new schema-based approach that tries to counter this behaviour. Therefore, we first design our own schema and give ideas on how test cases can look like. We then implement exemplary test cases and describe this step in detail to give ideas on how to build own ones. At last, we evaluate a cross-section of forensic tools with the test cases and find out that our implementation work is well-suited to find flaws in today's forensic software products. We conclude that there is still much work to be done to enhance security against the anti-forensic threat.
An anonymised version of the thesis,
omitting details about the tested software products can be
downloaded here.
This censoring is done alongside the idea of responsible
disclosure and should give every vendor enough time to respond
to the flaws found in their products.
Testing software completely without missing any use cases is quite difficult. The approach of proving correctness via analyses on the source code level might be feasible for small projects but is impossible on a scale that more complex programs typically have.
A schema is sort of a guideline that helps practitioners to test their tools. By carefully designing such a schema one tries to cover as much aspects as possible, thus providing a good approach to testing.
Existing schema designs are unsuitable in different ways.
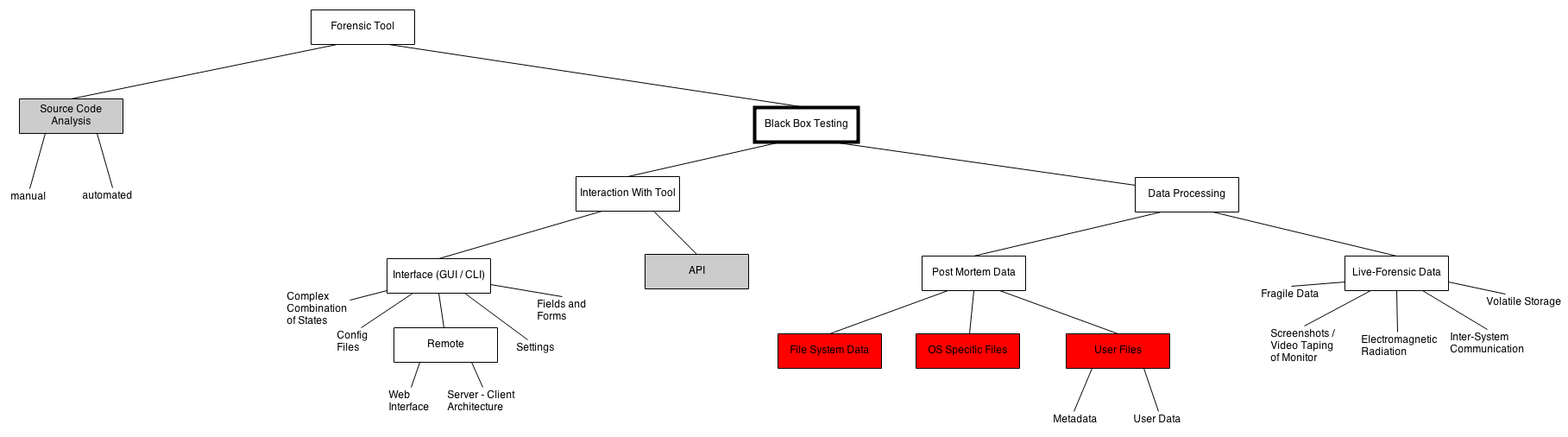
To faciliate this task I created a schema that borrows ideas of other work but focuses on the act of testing.
Starting with the forensic tool itself on the most basic level a tree-based structure has been created that organises different kinds of input in subcategories.
Not all of them may apply to every tool. However, they are all important as they are designed to represent every input type that could possibly be made.
As one can imagine a schema tree covering every input grows extremely fast. Due to the time constraints imposed to a Bachelor's thesis I had to choose a smaller subset to exemplarily design actual test cases. I chose the different types of Post Mortem Data coloured in red for the following reasons:
The findings made with these test cases (see thesis) illustrate the power of a structured testing approach. Nevertheless, the full potential of STARFiSH can only be achieved if it is further enhanced. If you think that you could provide more test cases or have ideas for improvement please have a look at the contribution section down below.
The test cases created during my thesis target very different parts
of forensic software, starting on a low (file-system) level and
working up to the application level.
However, all test cases are described in a formally comparable way,
such that one can gain a quick insight into what should be achieved.
The formal descriptions of the following test cases can be found in
Appendix F of the above downloadable thesis.
If you wish to contribute own test cases, please describe them in the
same way. This latex template
should help you doing so (PDF preview).
| File System Data | OS Specific Files | User Files |
|---|---|---|
| FAT | Windows | Multimedia |
| OS_W_EDB_1 | OS_W_EDB_1 | UF_MM_PIC_1 |
| FS_DL_FAT_2 | OS_W_EDB_2 | UF_MM_PIC_2 |
| NTFS | OS_W_JL_1 | UF_MM_PIC_3 |
| FS_DL_NTFS_1 | OS_W_JL_2 | UF_MM_PIC_3 |
| HFS+ | OS_W_EVTX_1 | UF_MM_PIC_4 |
| FS_DL_HFS_1 | OS_W_EVTX_2 | UF_MM_PIC_5 |
| FS_DL_HFS_1 | OS_W_REG_1 | Office Files |
| EXT4 | OS_W_REG_2 | UF_OF_M_1 |
| FS_DL_EXT4_1 | OS_W_REG_3 | UF_OF_M_2 |
| Mac OS X | UF_OF_M_3 | |
| OS_M_BPL_1 | UF_OF_M_4 | |
| OS_M_BPL_2 | UF_OF_M_5 | |
| OS_M_BPL_3 | UF_OF_ODF_1 | |
| OS_M_LOG_1 | UF_OF_ODF_2 | |
| OS_M_LOG_2 | UF_OF_ODF_3 | |
| OS_M_LOG_3 | UF_OF_ODF_4 | |
| OS_M_SLDB_1 | Various Other User Files | |
| Linux | UF_V_CB_1 | |
| OS_L_BH_1 | UF_V_CB_2 | |
| OS_L_MLDB_1 | UF_V_CB_3 | |
| OS_L_MLDB_2 | UF_V_PDF_1 | |
| OS_L_MLDB_3 | UF_V_PDF_2 |
So far, the forensic community has not commited to STARFiSH.
As already stated, the work I did in my thesis is far from being complete.
Surely this is caused by the limited amount one has when writing a
Bachelor's thesis, but also by the fact that I as a single person
am not a professional in every existing forensic topic.
I invite everybody with knowledge in an area to produce
new test cases and send them to me so I can publish them on this site.
The idea is that by sharing the knowledge, an improved and more
bullet proof laboratory set up can be achieved for everybody.
I am as well open for criticism or improvement ideas related to the
schema.
Either way, mail your feedback or test cases to
knuefer (at) digitrace (dot) de.
Based on "STARFiSH", I wrote another Thesis (B.Sc.) here at DigiTrace. The title in German is "Wie gut erkennen IT-forensische Werkzeuge in Dateisystemen verborgene Daten?" (How well do it-forensics software recognize in filesystem hidden data?)
The goal is to examine known anti-forensic methods to hide data in filesystems (generic). The only existens of these methodes was a theoreticale spezification. It is unkown, if IT-forensics software is able to find the hidden data. Also there isn't any public test data or test tools to verify these methods.
I created test data (and tools to create the data) based on the known mehtods. I also defined criteria the test data and methods must meet. For example, the filesystems have to be usable and stand against checks like "fsck" and "chkdsk". I checked five it-forensic programs (commercial and free), if they are able to find the hidden data and how much effort an it-forensic expert would need to do so.
Aufbauend auf der Abschlussarbeit "STARFiSH", habe ich eine weitere Thesis (B.Sc.) im Hause DigiTrace verfasst.
Der Titel der Arbeit ist "Wie gut erkennen IT-forensische Werkzeuge in Dateisystemen verborgene Daten?".
Ziel und Zweck der Arbeit ist es bekannte antiforensische Methoden zum Verbergen von Daten zu untersuchen. Diese Arbeit bezieht sich dabei auf das generische verbergen von Daten in Dateisystemen (generic data hiding). Die verwendeten Methoden wurden theoretisch beschrieben, es wurde jedoch keine Aussage darüber getroffen, ob IT-forensische Werkzeuge (kommerzielle und öffentliche) die durch diese Methoden verborgenen Daten finden. Zudem gibt es keine Testdaten oder Testprogramme, um die bekannten Methoden zu testen.
Die Umsetzung der Methoden sowie die Erstellung der Testdaten und Programme werden in meiner Thesis behandelt. Die Testdaten, sowie die ausgewählten Methoden, müssen dabei festgelegte Kriterien erfüllen. Die Dateisysteme müssen beispielsweise noch nutzbar sein und müssen auch Dateisystemprüfungen wie fsck und chkdsk bestehen. Außerdem werden fünf IT-forensische Programme untersucht und geprüft, ob die Daten gefunden werden können und wenn ja mit welchem Aufwand.
| HFS+ | NTFS |
| FS_BB_HFS+ | FS_ADS_NTFS |
| FS_BT_HFS+ | FS_BB_NTFS |
| FS_SF_HFS+ | FS_BR_NTFS |
| FS_DA_NTFS |